To wrap up our discussion of data-ingest methods, we’ll consider Microsoft Excel workbooks. Many datasets, especially those shared outside of academia, are stored and distributed as Excel workbooks. Thankfully, when you encounter such datasets, you’ll have no problems loading the data because several R packages allow us to work with Excel workbooks.
For quick-and-easy data-ingest from an Excel workbook, the readxl package is a good option. We can load data from an Excel workbook with the readxl::read_excel() function.
# A tibble: 6 × 8
survived class name sex age siblings_spouses parents_children fare
<chr> <chr> <chr> <chr> <dbl> <dbl> <dbl> <dbl>
1 no 3rd Mr. Owen H… male 22 1 0 7.25
2 yes 1st Mrs. John … fema… 38 1 0 71.3
3 yes 3rd Miss. Lain… fema… 26 0 0 7.92
4 yes 1st Mrs. Jacqu… fema… 35 1 0 53.1
5 no 3rd Mr. Willia… male 35 0 0 8.05
6 no 3rd Mr. James … male 27 0 0 8.46
Notice that we need to specify which sheet holds our target data via the sheet argument. If we don’t specify a value for the sheet argument, read_excel() will read from the first sheet in the workbook.
If we only need to load data, then readxl will usually suffice, but we won’t be able to save data back to an XLSX workbook with readxl functions. So, if we want to write data back to an Excel workbook, we should consider a using different package. The openxlsx package is a good option.
The procedure for reading data with openxlsx is almost identical to what we did with readxl. In this case, we use the openxslx::read.xlsx() function.
survived class name sex age
1 no 3rd Mr. Owen Harris Braund male 22
2 yes 1st Mrs. John Bradley (Florence Briggs Thayer) Cumings female 38
3 yes 3rd Miss. Laina Heikkinen female 26
4 yes 1st Mrs. Jacques Heath (Lily May Peel) Futrelle female 35
5 no 3rd Mr. William Henry Allen male 35
6 no 3rd Mr. James Moran male 27
siblings_spouses parents_children fare
1 1 0 7.2500
2 1 0 71.2833
3 0 0 7.9250
4 1 0 53.1000
5 0 0 8.0500
6 0 0 8.4583
When we compare the two datasets, we see that they return functional equivalent objects. The only notable difference is that readxl::read_excel() returns a tibble while openxlsx::read.xlsx() returns a Base R data frame.
str(titanic1)
tibble [887 × 8] (S3: tbl_df/tbl/data.frame)
$ survived : chr [1:887] "no" "yes" "yes" "yes" ...
$ class : chr [1:887] "3rd" "1st" "3rd" "1st" ...
$ name : chr [1:887] "Mr. Owen Harris Braund" "Mrs. John Bradley (Florence Briggs Thayer) Cumings" "Miss. Laina Heikkinen" "Mrs. Jacques Heath (Lily May Peel) Futrelle" ...
$ sex : chr [1:887] "male" "female" "female" "female" ...
$ age : num [1:887] 22 38 26 35 35 27 54 2 27 14 ...
$ siblings_spouses: num [1:887] 1 1 0 1 0 0 0 3 0 1 ...
$ parents_children: num [1:887] 0 0 0 0 0 0 0 1 2 0 ...
$ fare : num [1:887] 7.25 71.28 7.92 53.1 8.05 ...
str(titanic2)
'data.frame': 887 obs. of 8 variables:
$ survived : chr "no" "yes" "yes" "yes" ...
$ class : chr "3rd" "1st" "3rd" "1st" ...
$ name : chr "Mr. Owen Harris Braund" "Mrs. John Bradley (Florence Briggs Thayer) Cumings" "Miss. Laina Heikkinen" "Mrs. Jacques Heath (Lily May Peel) Futrelle" ...
$ sex : chr "male" "female" "female" "female" ...
$ age : num 22 38 26 35 35 27 54 2 27 14 ...
$ siblings_spouses: num 1 1 0 1 0 0 0 3 0 1 ...
$ parents_children: num 0 0 0 0 0 0 0 1 2 0 ...
$ fare : num 7.25 71.28 7.92 53.1 8.05 ...
# Convert 'titanic1' from a tibble to an ordinary data frametitanic1.2<-as.data.frame(titanic1)# Are the two objects equivalent?all.equal(titanic1.2, titanic2)
[1] TRUE
Practice
Use both readxl::read_excel() and openxlsx::read.xlsx() to load the data from the “diabetes” sheet in the Excel workbook stored as “./data/example_data.xlsx”.
In addition to selecting the sheet from which we want to read our dataset, we can also specify the range of cells within that sheet that we want to read. This capability is particularly useful because Excel workbooks are typically organized as interactive spreadsheets that include additional, arbitrarily organized metadata cells and formula cells. These additional cells often violate the regular grid structure that we assume for a rectangular datasets.
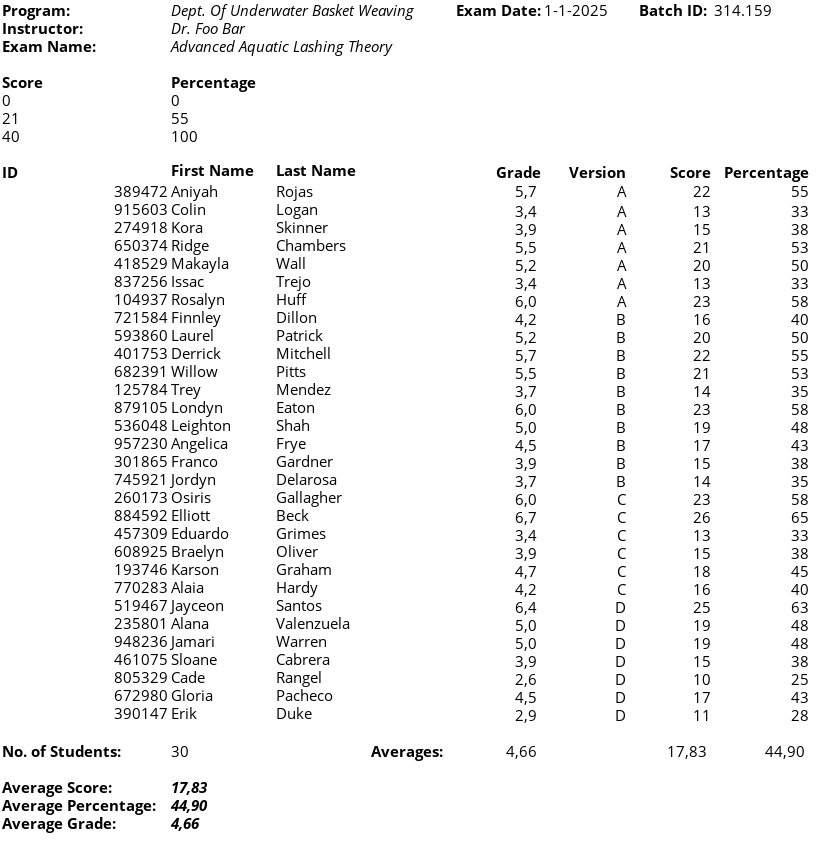
For example, the following image shows the “exam_results” sheet from the “./data/example_data.xlsx” workbook. This sheet contains an interactive spreadsheet that summarizes the results of a hypothetical exam. Notice how the sheet contains nine leading rows and six trailing rows of metadata surrounding the 31 rows of individual exam results (and column names). If we’re interested in the individual exam results, the extra metadata rows will cause problems.
If we try to read all the data in this sheet, we get the following results.
The extra metadata rows break the rectangular grid structure and interfere with our ability to access the individual exam results. Furthermore, the first row of metadata is interpreted as column names, which doesn’t make any sense in this case.
Fortunately, both read_excel() and read.xlsx() provide options for restricting the range of cells that we read. In the following code chunks, we use the range and rows arguments to read only the rectangular grid of individual exam results.
# A tibble: 20 × 8
ID `First Name` `Last Name` ...4 Grade Version Score Percentage
<dbl> <chr> <chr> <lgl> <dbl> <chr> <dbl> <dbl>
1 389472 Aniyah Rojas NA 5.7 A 22 55
2 915603 Colin Logan NA 3.4 A 13 33
3 274918 Kora Skinner NA 3.9 A 15 38
4 650374 Ridge Chambers NA 5.5 A 21 53
5 418529 Makayla Wall NA 5.2 A 20 50
6 837256 Issac Trejo NA 3.4 A 13 33
7 104937 Rosalyn Huff NA 6 A 23 58
8 721584 Finnley Dillon NA 4.2 B 16 40
9 593860 Laurel Patrick NA 5.2 B 20 50
10 401753 Derrick Mitchell NA 5.7 B 22 55
11 682391 Willow Pitts NA 5.5 B 21 53
12 125784 Trey Mendez NA 3.7 B 14 35
13 879105 Londyn Eaton NA 6 B 23 58
14 536048 Leighton Shah NA 5 B 19 48
15 957230 Angelica Frye NA 4.5 B 17 43
16 301865 Franco Gardner NA 3.9 B 15 38
17 745921 Jordyn Delarosa NA 3.7 B 14 35
18 260173 Osiris Gallagher NA 6 C 23 58
19 884592 Elliott Beck NA 6.7 C 26 65
20 457309 Eduardo Grimes NA 3.4 C 13 33
That’s better! Now, we have nice rectangular data frames containing only the interesting data.
Practice
Use the openxlsx::read.xlsx() function to load the first 100 rows (not counting column names) of the first 4 columns from the ‘diabetes’ sheet in the Excel workbook stored as “./data/example_data.xlsx”.
Use the readxl::read_excel() function with an appropriate specification for the range argument to load the chunk of data beginning on Row 3 and Column 2 and ending on Row 100 and Column 7 from the ‘titanic’ sheet in “./data/example_data.xlsx”.